What Is Legal Analytics?¶
Legal Analytics is the practice of extracting machine-readable knowledge from legal data in order to use that data to improve matter scoping, legal strategy, cost and billing optimization, resource management, and financial operations. Instead of making causal inferences about a particular problem, an organization can utilize legal analytic techniques to build predictive machine learning models that can analyze and solve a wide range of legal-related problems.
Analytics vs. Cognitive Biases¶
Some of the most powerful thoughts and beliefs we hold are based on cognitive biases. Confirmation Bias, the Dunning-Kruger Effect, the Framing Effect, and the Status Quo Bias are some of the best-known and most pervasive. The clash of correlation versus causation is perhaps the most infamous of them all.
Decision-making, even at the highest levels of a law firm, law department, or financial institution, can be influenced by these and other cognitive biases. Machine learning (ML) techniques analyze raw data and create predictive models, with the goal of drastically reducing human biases. A well-trained and generalizable data model can streamline decision-making in virtually any arena, and we believe that law is no exception.
The Black Swan Problem¶
The Black Swan Problem isn’t a cognitive bias, but must be understood alongside biases when building any kind of predictive model. The Black Swan Problem can be stated in the following way:
Even though most swans we find in nature are white, this does not mean that all swans will always be white. Sometimes, we may observe a black swan in nature.
Technology is developing at a rapid rate, and the amount of raw data in the world increases exponentially every day. With such a massive amount of data, ordinary assumptions and conventional logic can be cumbersome and imprecise. Models built on past experience may be on shaky ground. The Black Swan Problem is a cautionary illustration of the dangers that can occur when using overly simplistic, or under-developed predictive models. There are “unknown unknowns” within any system, and though they are by definition unpredictable, they must always be considered as possibilities.
If analytics is to do more than model data that already exists - if we want a truly predictive model - then we have to dispense with the notion of a data environment that the human mind can master unaided. To build a superior predictive model, we must:
Consider the potential for outliers in a system, and
Do our best to incorporate these potentials into a predictive model, so that
We can respond effectively to unforeseeable shifts – both gradual and dramatic – within a system
Machine Learning (ML)¶
ML is a form of artificial intelligence (AI) in which a computer learns how to classify data of various types without being explicitly programmed how to do so. ML techniques are used to develop predictive models, but in order to build these models, good data must first be collected and fed into a platform like ContraxSuite. Organizations can use ContraxSuite to collect data on contracts, as well as data on cases, clients, personnel, communications, risk management procedures, and even certain forms of quantifiable uncertainty. Any record of fact should be included in the data collection process. The more, the better. Once this data is collected, ML is used to build predictive models.
In this way, ML is not unlike the way we humans evolved to learn from patterns in our environment, adapting our behaviors to those patterns in order to thrive. At its core, ML is the synthetic equivalent of eating a poisonous berry, getting sick, and avoiding that berry in the future. But what if the berry isn’t poisonous, just rotten? Or what if something else in the environment made us sick, independent of the berry? We may see patterns where none exist, and we may miss patterns that do exist. We may encounter a Black Swan. What then?
Human learning is fallible, and if we are not careful, our blind spots can hinder the development of ML models. Correlation can be incorrect, and causation can be imprecise. To combat these errors and inefficiencies, we need a better understanding of two core concepts involved in building ML models: training data, and generalization.
Training Data¶
Building predictive ML models requires training data. Training data must be representative of the type of data that the model will ultimately use in practice. An organization’s specific needs will dictate what constitutes good training data. If the goal is to improve the efficiency of a human resources system, for example, training data should probably come from HR, not from the accounting department. Good training data needs to be diverse and comprehensive within set parameters, but it also needs to have a set of decision trees within it that are not overly specific. Generalization can help with this process.
Generalization¶
Generalization is the ability of an ML model to perform accurately on new, unseen examples and tasks, after being initially trained using training data. First, a predictive ML model is built using training data. Then, after the training period, the model is fed additional relevant data. The ultimate goal is that the model built from the original training data responds to new data with high efficacy, and continues to build upon initial success with additional new data.
Decision Trees¶
There are some problems that can occur when trying to make a predictive ML model generalizable. If a model is not well generalized, or if training data is not adequate, these problems can render an ML model ineffective.
To refine an ML model, we look closely at the set of decision trees that the training data has created. A decision tree is a visual representation of all the potential outcomes of a series of decisions. Each decision is represented as a node, and possible outcomes split off of each node like tree branches, creating various levels of specificity. A predictive ML model uses these decision trees to account for complex probabilities.
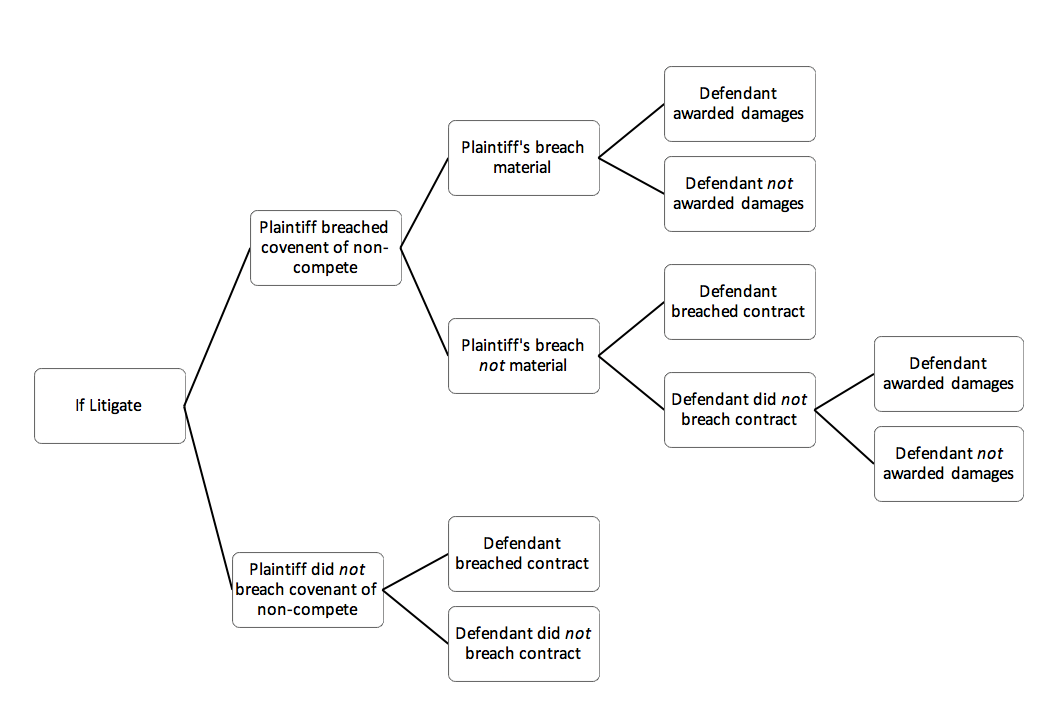
An example of a decision tree
Problem: Overfitting¶
If decision trees are too narrowly formed, then a predictive ML model runs the risk of being overly complex and specific to its initial training data. This overfitting defeats the purpose of model building in the first place. A model’s efficacy is determined not by performance on training data alone, but by its ability to generalize and perform well on unseen data. Overfitting is what happens when a decision tree is overly large and the model begins “memorizing” the training data, rather than creating a more generalizable model. An overfit ML model ignores underlying patterns, and retains outliers rather than excluding them.
Solutions¶
There are several ways to resolve the overfitting problem. Pruning is a technique that reduces the size of decision trees by removing sections that do not add significant predictive power to the model. If a node on a decision tree is not providing much additional information to the model, then the model can probably be improved by “pruning” that “branch” of the decision tree. The goal of pruning is to reduce the size of a decision tree without reducing the predictive accuracy of the model.
Another way to strengthen a model is through cross-validation. This process begins after data collection. Instead of forming only one training data set, two similar training data sets are formed from the total pool of training data. One set is used for training purposes, while the second is used as a kind of control, or testing set. Once the data has been partitioned into two sets, the training data is used to train the ML model, and then the testing set is run through the model to establish its validity and whether or not the model has been overfit to the first set of data. To increase the model’s robustness and reliability, multiple rounds of cross-validation can be performed using different data combinations in new training sets and testing sets.
The Random Forest Method is another technique for enhancing the efficacy of predictive ML models. This technique involves gathering training data, and then partitioning that data into a training set and multiple testing sets, with some overlap between sets in order to establish cross-validation. Creating multiple testing sets results in the creation of similar, but distinct, decision trees. The resulting “random forest” of decision trees will lead to more dependable ML models.
The power of a random forest is that even if one tree possesses a weakness, the amount of trees means that these weaknesses will be compensated for by the aggregation of every tree’s differing point of view. This in turn reduces complications such as overfitting. Taken together, the separate trees in the forest will have immense predictive power. This aggregating technique reduces the potential for knowledge gaps that might negatively impact an organization’s data strategy.
If you’re interested in learning more, visit the LexPredict blog for a full series of posts covering the topics on this page: